DynamoGuard On-Device
DynamoGuard's on-device solution enables policy guardrails to be run fully on-device, enabling further privacy and security. On-Device enables you to run guardrail models on-device, using a hybrid cloud/edge environment. Guardrail models run on-device and make external calls to your secure cloud-hosted LLM.
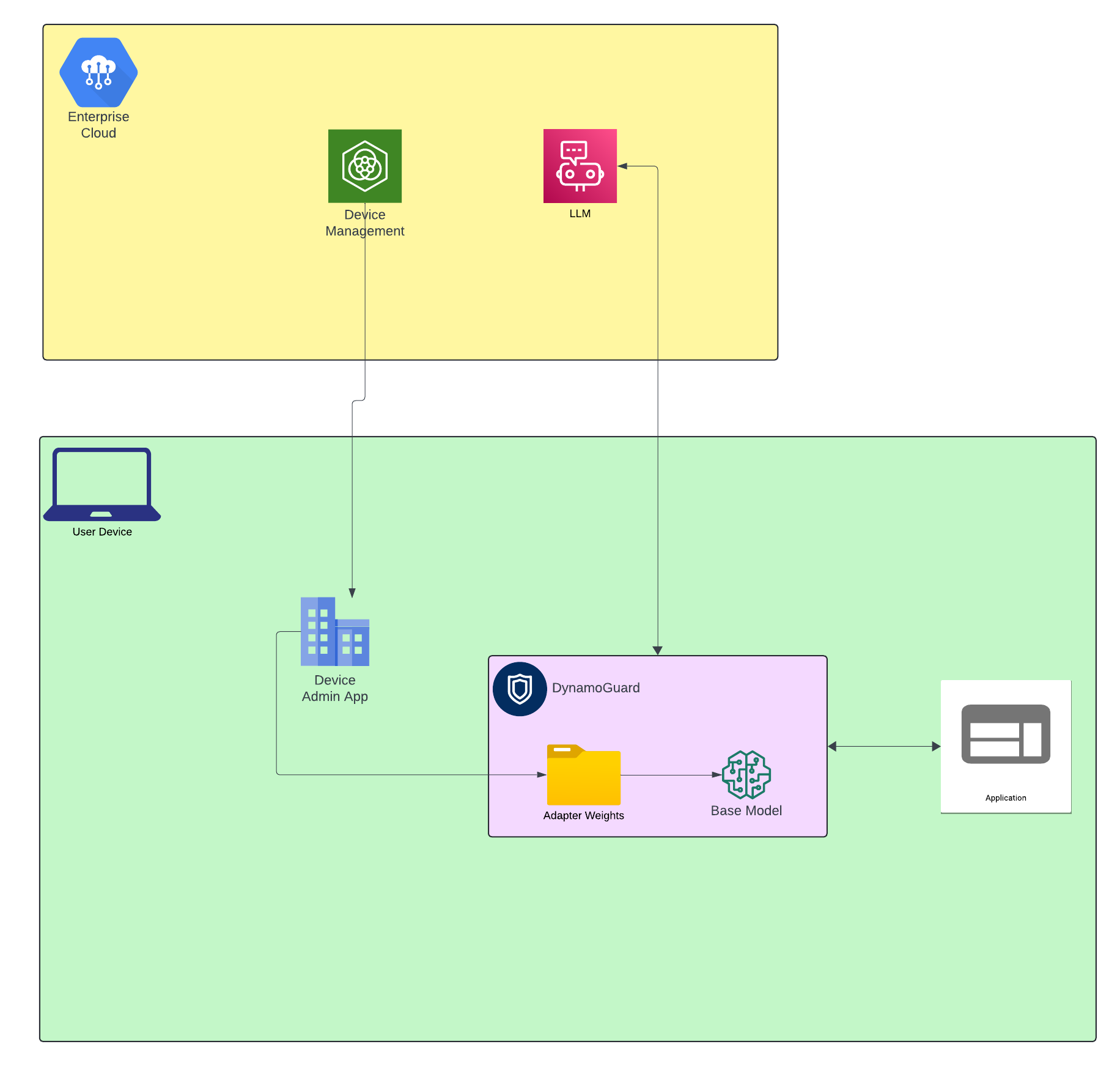
How it Works
- To install DynamoGuard On-Device, the device must first go through a one-time installation of a 1.6B base model. Additional custom guardrails can be installed using LORA adapter weights. Enterprises can securely add/remove adapter weights as needed through the device administration app
- When an application on the device makes an external LLM call, first a request to DynamoGuard On-Device is sent. The correct adapter for the task is loaded onto the CPU/GPU/NPU, fused with the base model, and then inference is run on the user input
- If the user input is deemed safe, it is then forwarded to the external LLM
- After recieving the LLM response, DynamoGuard On-Device is again leveraged to check if the response is compliant. If determined to be compliant, the response is sent back to the application